このサイトでは、NCデータの解析・変換などの自作アプリを公開しています。
これまでは C++Builder で自作ライブラリを作成し開発してきました。
独学ゆえに効率や可読性など課題は沢山ありますが、いまさら見直す気にもなりません。
最近は Python の学習もかねてNCデータ解析ライブラリのpythonへの移行を考えています。
AI の登場で、素人でも高度なコードを得られる時代になりましたが、意味を理解せずに使うのはやはり危険ですし、プログラミングスキルは向上しません。
この記事を書くきっかけは
「Fanuc系NCブロックをNCワードに分割させる、pythonスクリプトをだして」
へのAIの回答に正規表現が使われていた事から始まりました
本記事では、「一見意味不明な呪文のような正規表現」を理解して行く過程を記事にしました。
正規表現
正規表現の情報は、ネット上に豊富にあると思うので、詳細は検索してみてください。
下記は「正規表現」の説明をAIに聞いてみた回答です
概要
本チャットログでは、「正規表現(Regular Expression)」の基本要素について、最小限かつ代表的な機能に絞って説明している。主な用途は文字列の検索・置換・抽出であり、「文字列パターンを表現する小さな言語」として位置付けている。
1. 文字列とリテラル
- abc
- 文字列「abc」にそのままマッチするパターン。
2. メタ文字(特別な意味を持つ記号)
- . : 任意の1文字
- ^ : 行頭
- $ : 行末
- * : 直前要素の0回以上の繰り返し
- + : 直前要素の1回以上の繰り返し
- ? : 直前要素の0回または1回
- | : OR(または)
- () : グループ化・キャプチャ
具体例
- a.*b
- 「a」で始まり「b」で終わる行全体にマッチ(間の文字列は任意長)
- colou?r
- color または colour にマッチ(u がある/ない両方に対応)。
3. 繰り返し回数の指定(量指定子)
- {n} : ちょうど n 回
- {n,} : n 回以上
- {n,m} : n〜m 回
具体例
- \d{3}-\d{4}
- 123-4567 のような「数字3桁-数字4桁」形式にマッチ。
4. 文字クラス
- [abc] : a か b か c のいずれか1文字
- [^abc] : a,b,c 以外の1文字
- [0-9] : 数字
- [A-Za-z] : 英字(大文字・小文字)
5. 代表的なエスケープシーケンス
多くの処理系で共通して使われるもの。
- \d : 数字 [0-9]
- \w : 単語構成文字(英数字 + _)
- \s : 空白文字(スペース・タブ・改行など)
- \D : 非数字(\d 以外)
- \W : 非単語構成文字(\w 以外)
- \S : 非空白文字(\s 以外)
6. エスケープが必要な記号
次の文字はメタ文字として特別な意味を持つため、そのままの記号として扱うにはバックスラッシュでエスケープする必要がある。
- 対象文字
- . * + ? ^ $ ( ) [ ] { } | \
- 使用例
- \. : ドットそのものにマッチ
- \? : 疑問符そのものにマッチ
補足
ここまでが「基本の道具」としての正規表現の要素一式であり、今後はこれらを組み合わせて「メールアドレスの簡易チェック」など、実用的なパターン作成にも応用できると示唆している。
個別でみれば、なんとなくわかる気もしますが、これが組み合わさると、まったく呪文です
ただ、いろんなパターンの質問とAIの回答を照らし合わせると、なんとなく理解できてくるので、正規表現にかぎらず、AIは言語学習資料としても本当に役立ちます。
ファナック系、NCデータ構造
NCデータの分析ソフトを検討する場合、NCデータ構造の知識は必須です
NCデータの知識がないまま、AIの回答だけで進めると、間違いなく後々苦労します
ファナック系のプログラム構造は、下記記事でも紹介しています

「ワード」=「アドレス」+「数字・数値」
「ブロック」=「ワード」の集まり
「NCデータ」=「ブロック」の集まり
NCブロックからNCアドレスを抽出する課題なので、NCコードを少し復習しておきます
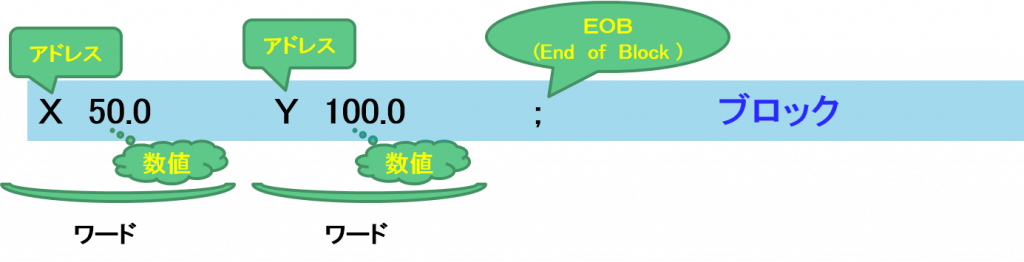
ブロックの末尾は制御器では「EOB」ですが、PC側では改行コードになります
改行コードはOSにより変わりますが、基本的にアスキー形式での転送で大丈夫だと思います
NCデータの最小単位は、「ワード」と呼ばれていて、
「アルファベット一文字」+「数字、符号、小数点」が一塊になっている要素です
例えば「G02」とか「X-12.345」の構成です。
先頭のアドレス文字で機械への指令の種類を表し、ワードで具体的な指令になります
この「ワード」が集まり、一行の構成になった文字列が「ブロック」と呼ばれます
さらに、「ブロック」が複数行あつまって、NCデータになります
CAM利用の場合、作成したNCデータファイルをNC機械へ転送し加工動作を制御します
分析ソフトを検討する場合、まずはNCデータをブロックに、ブロックをワードに分解したほうが整理しやすいです
今回の課題では、正規表現を利用して「ブロック」を「ワード」に分解するコードを作成します
やりたい事をAIに投げかけると、それなりの回答をもらえます。
ただ、NCコードのように、機種依存や複雑な表現がある場合、AIへすべて完ぺきなコードを期待してもなかなか思うような回答は得られません。
また、最初は良くても開発を進めていくうちに、改造したくなる場合もあります
やはり、ある程度の理解は必要です。
ブロックから正規表現でワードに分解する
具体的に正規表現を書き、「ワード」に分解した結果と照らし合わせながら理解を進めようと思います
「ワード」=「大文字アルファベット一文字」+「数字」なので、一番単純な正規表現のパターンは、”[A-Z]\d”になります
また、正規表現パターンで、文字列から部分文字列を抽出するのに、AIは「re.findall関数」を教えてくれました
(findall関数についての詳細は、ネット検索やAIに聞いてみてください)
サンプル文字列は複数のパターンを織り交ぜた、”G0G1G00 G03M3 T102M30″ でやってみます
(文字列並びのみのサンプルで、NCデータとしては意味ありません)
アドレスと数字抽出
import re
block = "G0G1G00 G03M3 T102M30" # サンプルNCブロック文字列
words = re.findall(r"[A-Z]\d", block)
print(f"{words}")
#---------- 結果 --------------
#['G0', 'G1', 'G0', 'G0', 'M3', 'T1', 'M3']ちょっと期待とは違いますが、とりあえずは、アドレスと数字がリストで取り出せました
たった一行で分解された文字列リストが作成されました、すごいですね~
一文字づつ文字列操作で処理させたら、結構なコード量になっていると思います
ただ、「\d」としたため、「数字は一文字」しか抽出してくれませんでした
ここで「\d{2}」としてみると、「数字二文字」のみ取り出してくれます
今回の例ですべて取り出すには「\d{1,3}」とすればすべてヒットします
「\d+」でも同様の結果になりますが、こちらの方は文字数制限はなくなります
今回のサンプルでは、”[A-Z]\d+”で行こうと思います
ちなみに、「\d{0}」とすると、アドレスのみ取り出せます。
import re
block = "G0G1G00 G03M3 T102M30" # サンプルNCブロック文字列
words = re.findall(r"[A-Z]\d+", block)
print(f"{words}")
#---------- 結果 --------------
#['G0', 'G1', 'G00', 'G03', 'M3', 'T102', 'M30']さらに、アドレスと数字を分けて抽出したい場合
グループ化と呼ばれる(丸括弧)でパターンを囲むと「tuple」として分離してくれます
抽出した後の処理内容によっては、こちらが便利かもしれません
import re
block = "G0G1G00 G03M3 T102M30" # サンプルNCブロック文字列
words = re.findall(r"([A-Z])(\d+)", block)
print(f"{words}")
for addr, val in words:
print(f"addr={addr}:val={val}")
#---------- 結果 --------------
#[('G', '0'), ('G', '1'), ('G', '00'), ('G', '03'), ('M', '3'), ('T', '102'), ('M', '30')]
#addr=G:val=0
#addr=G:val=1
#addr=G:val=00
#addr=G:val=03
#addr=M:val=3
#addr=T:val=102
#addr=M:val=30軸(X,Y,Z・・)の小数点にも対応させる
ここまでは、GやMコードでしたが、軸指令に対応するには、符号や小数点も考慮する必要があります
余談ですがプログラミング初心者の場合勘違いしやすいのが、数字と数値の違いです。
「12.23」の場合、数値としては「12 + 0.23」のように演算ができますが、
数字の場合は、「1」「2」「.」「2」「3」と途中に「.」があるだけのただの数字文字の連続です
正規表現の場合も、数字・符号・小数点の文字の集まりとして処理するので、数値で考えてしまうと期待と違う結果になり、悩む事になります
さて、文字を意識してサンプル文字列データに軸指令を追加して、上記のコードで実行してみます
import re
block = "G90G01 X12.5Y+20.3Z-5.63F1000" # サンプルNCブロック文字列
words = re.findall(r"[A-Z]\d+", block)
print(f"{words}")
#---------- 結果 --------------
#['G90', 'G01', 'X12', 'F1000']やはりこのコードでは、±符号と小数点が入るとマッチしないので、省かれてしまいますね
まず符号に対応するためにはアドレス「A-Z」の後に[+-]を追加します
import re
block = "G90G01 X12.5Y+20.3Z-5.63F1000" # サンプルNCブロック文字列
words = re.findall(r"[A-Z][+-]\d+", block)
print(f"{words}")
#---------- 結果 --------------
#['Y+20', 'Z-5']これでは、符号「+-」が必須に判断され符号付の文字列しかヒットしませんでした
符号文字は「無くてもいい」の意味で[+-]?としてみます
import re
block = "G90G01 X12.5Y+20.3Z-5.63F1000" # サンプルNCブロック文字列
words = re.findall(r"[A-Z][+-]?\d+", block)
print(f"{words}")
#---------- 結果 --------------
#['G90', 'G01', 'X12', 'Y+20', 'Z-5', 'F1000']符号部分を[+-]? とすることで、符号がなくてもマッチするようになりました
次に小数点とそれ以下にも対応させてみましょう
NC制御器は、数値として扱いますが、文字としての小数点の扱いは結構面倒です。
小数点がある場合、ない場合、小数点から始まる場合、小数点で終わる場合・・など
まずは、小数点の有無に対応させるため、「\d+\.\d+」を考えましたが、
この場合、小数点がないとマッチしなくなります
そこで「?を付加」すれば「無くてもいい」にも対応できます
import re
block = "G90G01 X12.5Y+20.3Z-5.63F1000" # サンプルNCブロック文字列
words = re.findall(r"[A-Z][+-]?\d+\.?\d+", block)
print(f"{words}")
#---------- 結果 --------------
['G90', 'G01', 'X12.5', 'Y+20.3', 'Z-5.63', 'F1000']
だいぶ理想に近づいてきましたが、「X.124」や「23.」など、小数点での始まりや終わりには対応できません
サンプル文字列に追加して確かめてみましょう
import re
block = "G90G01 X12.50Y+20.3Z-5.63 I.5 J22.F1000" # サンプルNCブロック文字列
words = re.findall(r"[A-Z][+-]?\d+\.?\d+", block)
print(f"{words}")
#---------- 結果 --------------
#['G90', 'G01', 'X12.50', 'Y+20.3', 'Z-5.63', 'J22', 'F1000やはり、「I.5」にはマッチせず「J22.」の「.」は省かれていますね
ここも余談ですが、NCで「22.」を「22」に変換してしまった場合、制御器によってはとんでもない事になりかねないので十分意識しておく必要があります。
整理してみると
- [A-Z]:NCコードのアドレス
- [+-]?:必須ではない、符号
- \d+:複数個の数字
ここまでで、「Gコード」「Mコード」には対応できている - \.?:小数点は必須でない
- \d+:複数個の数字
やはり、「小数点で終わる」場合「\.?」なので、省略されてしまいますね
ではどうすればいのか?
AIに聞いたところ、グループ化と言う方法があり、”( )”で囲む事で、一塊としてでマッチングのルール設定できるようです
ただし、”( )”では、囲みごとに分割されタプルのリストとして抽出されます
グループごとに分割させたくない場合には“(?: )“で囲む仕様があり非キャプチャグループと呼ばれマッチングのルールには使用するが分割はされないようです。
今回の例では、分割させたくないので、”(?: )“を使ってみます
最後の「\d+:複数個の数字」をグループ化して、必須ではない複数個の数字として設定します
import re
block = "G90G01 X12.50Y+20.3Z-5.63 I.5 J22.F1000" # サンプルNCブロック文字列
words = re.findall(r"[A-Z][+-]?\d+\.?(?:\d+)?", block)
print(f"{words}")
#---------- 結果 --------------
#['G90', 'G01', 'X12.50', 'Y+20.3', 'Z-5.63', 'J22.', 'F1000']これで、「22.」には対応できました。次は、小数点で始まる「.5」の場合です。
ここまででも、結構な呪文になっているのに、さらに複雑になりそうです。
ここもAIに相談すると、グループの中で(A | B)の書式で「AまたはB」とマッチング範囲の選択ができるようで、この書式での書き方を教えてくました
import re
block = "G90G01 X12.50Y+20.3Z-5.63 I.5 J22.F1000" # サンプルNCブロック文字列
words = re.findall(r"[A-Z][+-]?(?:\d+\.\d+|\d+\.|\.\d+|\d+)", block)
print(f"{words}")
#---------- 結果 --------------
#['G90', 'G01', 'X12.50', 'Y+20.3', 'Z-5.63', 'I.5', 'J22.', 'F1000']- [A-Z]:NCコードのアドレス
- [+-]?:必須ではない、符号
- — ここからグループ化 —
- \d+\.\d+:数字+小数点+数字
または - \d+\.:数字+小数点
または - \.\d+:小数点+数字
または - \d+:複数個の数字のみ
書き方は他にもあると思いますが、グループ化して、マッチさせたいパターンを一つ一つORで区切るこの方法は私には理解しやすかったです
複雑な正規表現の可読性を高める
いちおう動作はしましたが、ここまでくると、読みにくいですね~
可読性を高める方法として、さらにAIが「re.VERBOSE」を提案してくれました
具体的に、上記のコードを書き替えてみます
パターンを一行づつに分割できて、行ごとにコメントも追記できるので、複雑になってもわかりやすくなります
pattern = re.compile(
r"""
[A-Z] # A-Zアドレス
[+-]? # 符号
(?: # 小数点処理、非キャプチャグループ
\d+\.\d+ # 数字、小数点、数字
|\d+\. # または、数字、小数点
|\.\d+ # または、小数点、数字
|\d+ # または、数字のみ
)
""",
re.VERBOSE,
)
words = pattern.findall(block)
print(f"{words}")
#---------- 結果 --------------
#['G90', 'G01', 'X12.50', 'Y+20.3', 'Z-5.63', 'I.5', 'J22.', 'F1000']さらにちょっと特殊な、G や M コードにも対応させてみます
通常、NCワードは「アドレス+数字」ですが、拡張されたワーク座標系指令やサブプロ呼び出しなどちょっと特殊な構成のコードもあります
全てに対応は難しいと思いますが、「G54.1P1」や「M98P100」などにも対応してみようと思います。
これら対応するためには、上記のパターンでは処理できないのでパターンを追加します
やはり、可読性が上がる、re.VERBOSE を利用します
block = (
"G05P10000 G90G01 X12.50Y+20.3Z-5.63 I.5 J22.F1000 G54 G54.1P12 M98P1100 M198 P2299"
)
pattern = re.compile(
r"""
# --- 特殊構成、G54.1P12 / M98P1234 など---
[GM] # G や M アドレス
\d+(?:\.\d+)? # 54 や 54.1
\s*P\d+ # スペースとP文字と数字
# --- 通常のアドレス+数字 ----
|[A-Z] # A-Zアドレス
[+-]? # 符号
# --- 小数点対応 ----
(?: # 非キャプチャグループ
\d+\.\d+ # 数字、小数点、数字
|\d+\. # または、数字、小数点
|\.\d+ # または、小数点、数字
|\d+ # または、数字のみ
)
""",
re.VERBOSE,
)
words = pattern.findall(block)
print(f"{words}")
#---------- 結果 --------------
#['G05P10000', 'G90', 'G01', 'X12.50', 'Y+20.3', 'Z-5.63', 'I.5', 'J22.', 'F1000', 'G54', 'G54.1P12', 'M98P1100', 'M198 P2299']どうにかできました。
次の課題は「G04X10.」とかにも対応したいと思っていますが、これ以上条件が増えると大変です
正規表現パターンを変数化できれば、もう少しわかりやすいと思います
正規表現のraw文字列の変数化
AIに聞いてみました。さすがAI、できますよ!との回答をもらいました
AIの回答を参考に上記コードを書き直してみました。
block = (
"G05P10000 G90G01 X12.50Y+20.3Z-5.63 I.5 J22.F1000 G54 G54.1P12 M98P1100 M198 P2299"
)
num = r"[+-]?(?:\d+\.\d+|\d+\.|\.\d+|\d+)" # +12.123|-24.|.56|30
g54_1 = r"[GM]\d+(?:\.\d+)?\s*P\d+\.?" # G54.1P1 M98P1122
nomal = r"[A-Z]" # 通常のアドレス
pattern = re.compile(
rf"""
{g54_1} # G54.1P1 , M98P1122
#----------------------
|{nomal}{num} # G01 , X-12.356
""",
re.VERBOSE,
)
words = pattern.findall(block)
#---------- 結果 --------------
#['G05P10000', 'G90', 'G01', 'X12.50', 'Y+20.3', 'Z-5.63', 'I.5', 'J22.', 'F1000', 'G54', 'G54.1P12', 'M98P1100', 'M198 P2299']なるほど、だいぶ見やすくなりました
今後の仕様変更にも対応しやすくなったと思います
興味ある方は是非、「G04X10.」への対応もやってみてください。
まとめ
これまでも単純な正規表現に触れる機会はありましたが、複雑な記述はまるで「呪文」のようで、敬遠していました。
しかし、正規表現は文字列操作において非常に強力な武器になります。
独学ではやる気なしでしたが、AIと対話する事で、ある程度は理解できてきました。
今後もAIと対話しながら一歩ずつ分析していくことで、正規表現だけでなく、プログラミング言語全体の理解力も深めていけると感じています。